
Working with text data is a necessary part of analysis but often overlooked in skill development. This leaves gaps in analysis and adds time and tedium to common tasks.
Your ability to work and manipulate text greatly enhances your workflow and effectiveness. Splitting keyword, ad text, or campaign structure allows you to gain deeper insights and find new patterns.
Too often I see people resort to doing this work by hand. Scrolling through a spreadsheet labeling them one by one. There are a few straightforward methods used to speed this process up.
In this article, we’ll cover a handful of concepts to get started in approaching the problem and extracting the necessary text.
The Problem
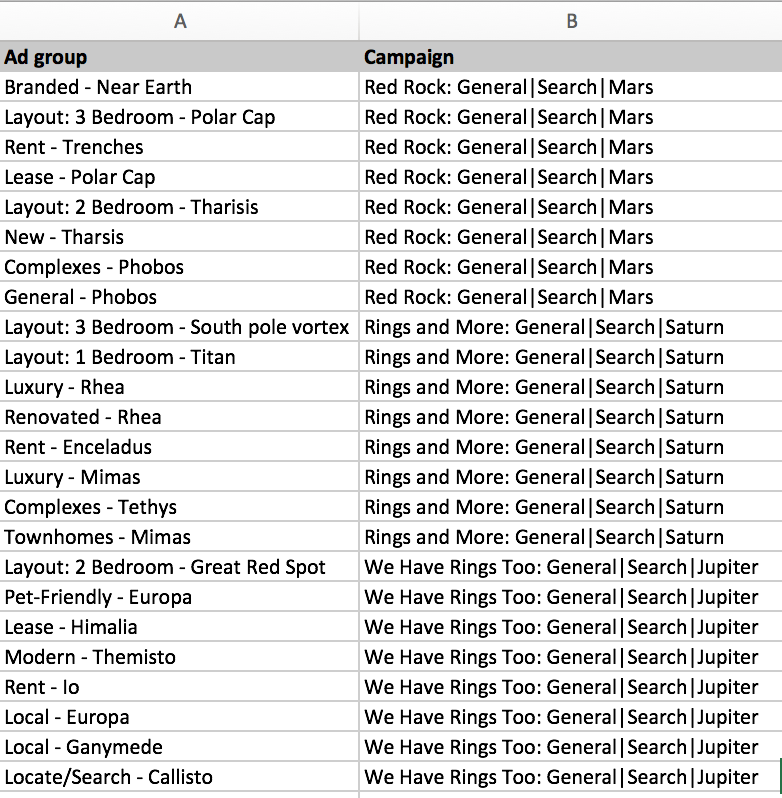
For the following examples, we’ll use a campaign and ad group structure from another account. In this scenario, we are currently in the process of restructuring it but need to extract a few components.
By expanding these components into a more a digestible format we will have a clear outline of what each location offers then use that with templates to build our new campaigns.
Setting Up
Below is our sample data.

Our first step is removing duplication. We have many of the same fields repeated but we only need to assign/extract the unique values once. If needed we can always use a lookup to reassign the extracted text to the necessary parts, such as campaign type or geographic targets to each campaign.
Let’s create a sheet with keys, the campaign and ad group, and all the extra values. This removes the chance of error in dragging and dropping. More importantly is reduces the load on yourself. When you review these to make sure everything lines up, you only have to check each key once.
Next, we need to define our questions,
- Where is the property located?
- What is the properties name?
- Are there surrounding neighborhoods to target?
Simple Solution – The Best Possible Scenario
In a perfect world, campaign naming conventions are consistent, spacing and delimiters are flawlessly implemented and you can split text to columns.
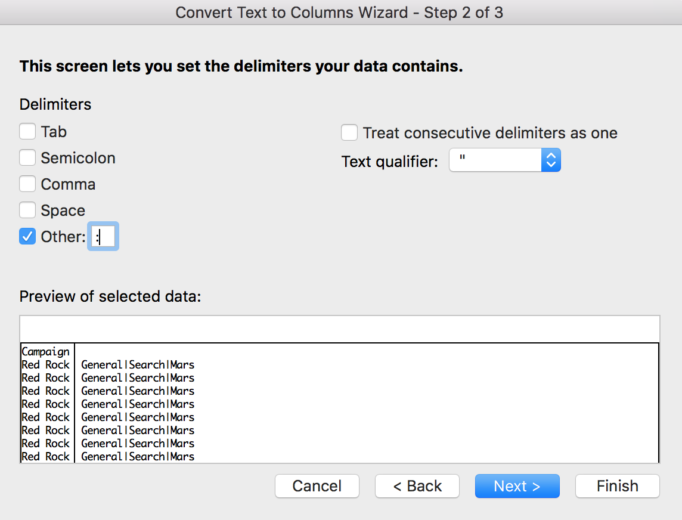
This tool will choose take delimiter (such as a hyphen, backslash, or space) and split the text along that piece. Each complement will be split into a new column so make sure you make room ahead of time or you may overwrite another column.
The one downside to this method is cleaning up if your text is all different lengths. The next section will provide an alternative if that is too cumbersome.
The More Flexible Solution
Let’s approach this from a different perspective. Instead of splitting the text, we’ll set up columns for each value then use formulas to pull out the desired text.
The first piece is easy. Looking at our Campaign names, we see the name of the property on the far left side and the location of the property at the far right. Everything to the left is the campaign, everything to the right is location information.
The Tools We Need
There are helpful functions to handle these types of situations. Left() and right() work by returning the text to the left or right of a given position.
These are straightforward to use on their own but can be extended by using search(). Search() returns the position of a character. Knowing that we can use it to pull from different places in the complete string.
Let’s jump into the specifics!
Property Name
The structure is consistent here and the property name is always the first set of characters ending in a colon. We can use the colon as the delimiter, use search() to find the position, and return all the characters to the left.
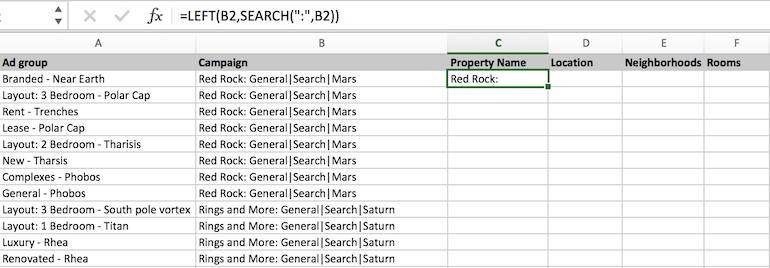
Something is off. We don’t want the colon there. We can fix this by subtracting one from the result of search().
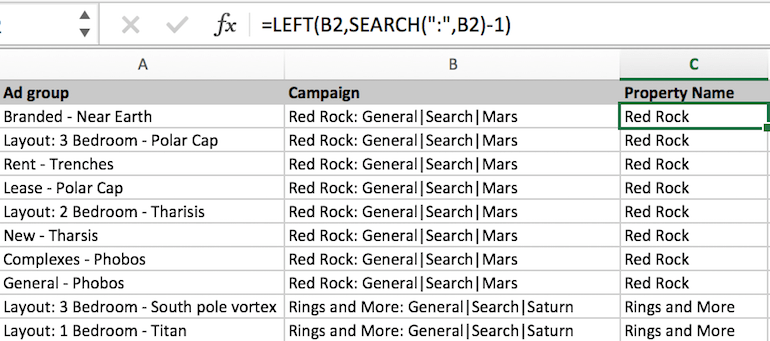
Why did we subtract? Since search() returns the position as a number, we can add or subtract from that number and alter which text is returned. In this case subtracting one removes the left most returned character and gets rid of the colon.
Location Name
Location name is slightly trickier as we have multiple pipes. We are working form the right side of the campaign name this time.
In order to get two pipes over we can chain two search() together to subset the first part then subset it again to get the rightmost word.
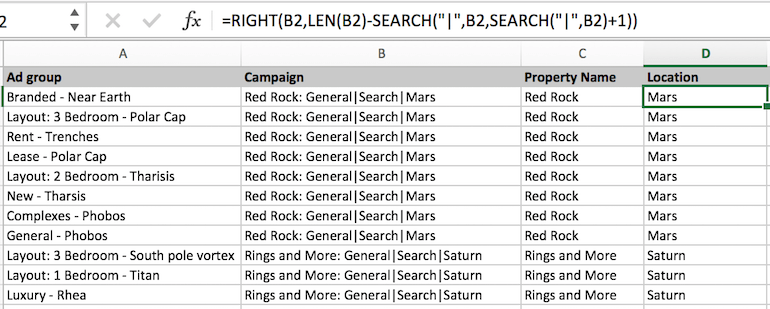
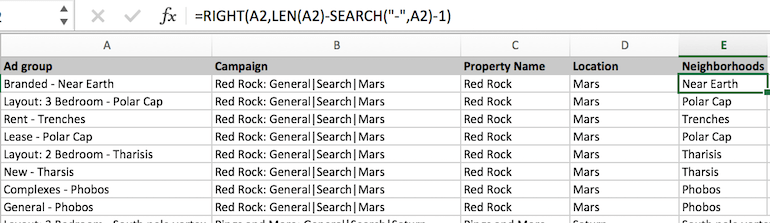
Neighborhoods
Now that we have location names we can find the surrounding neighborhoods. This is almost identical to the property name but we’ll pull from the right hand side of the ad group name.
The syntax may be slightly confusing as first. We use len() to see how long the string is. Then we subtract the number of characters from the start of the string to the hyphen, leaving the number of characters to the right of the hyphen.
Other Considerations
Sometimes parsing the exact text you need will be challenging. In these cases it is sometimes easier to clean the text beforehand.
Let’s say we wanted to extract the room details. Some locations don’t have this information. Rather than adding more logic to the steps we could filter out anything with “room”, ”townhouse”, etc. manipulate those and leave the rest of that column blank.
Sometimes it’s easier to delete or find and replace before you get to the functions. This can save a lot of time by removing unnecessary text and streamline your work even further.
Wrapping Up
Now that we have our key we can use it to tag our reports to easily segment between location, neighborhood, or property name. Or we could use this feed file to build new campaigns!
