
While we approach closing out yet another year, and while the question “When can this test conclude?” still comes up in my conversations at least once a week, I felt as though it was time to sit down and write out my test conclusion process and all the variables that factor into this decision.
Today, I’ll warm you up with two tips to keep in mind when you approach the decision of conclusion and then I’ll roll into the four variables that I look at when approaching this decision. Blow the dust off of that statistics textbook you buried long ago and let’s get started.
Preface Tip #1: Make Sure Your Data is Pretty and Robust
Before you set up your test, you should already know what your goals are. Notice how I said “goals” there. Yes, we all know you should have a centralized conversion; the one big thing you’re driving your users toward. But there are many other interactions with any site that we can track in order to observe whether or not our alteration affected those interactions as well. See the image below for a few examples.

Before you analyze any test data, double check that your data is all on an equal playing field. Ensure that you have pulled data for each goal for the same exact date range so that you can appropriately compare the data points without skewing one string of data. While you’re here, also make sure that all of your goal data looks “normal” and that you do not suspect any misfiring goals or dead goals that never saw any action.
Preface Tip #2: Never Conclude on a Single Variable
Making a conclusion decision cannot rely on any one variable. Take each of these four variables into consideration and if the majority of the variables compliment each other, then you can conclude with confidence.
If all of the variables are contradicting each other, you could be looking at a multitude of diverse scenarios. But at that point in time, if you conclude, you could be making an illogical decision with costly consequences.
Each of these variables is influenced by or affects at least one of the other variables. Thus, complementary data supports itself while contradictory data forces you to connect dots with webs of lies. Don’t do it!
Variable #1: Sample Size
Sample size matters folks. Sample size enables us to confidently generalize a behavior based on our population (total users) and our acceptable margin of error (100-goal statistical significance).
It’s really all about the proportions but if you’re consistently looking at the same site with very little traffic fluctuation then you can set a bottom line goal from which to work.
One hundred users to each segment of a test is a righteous bare minimum. Even on low traffic sites, it is very difficult to generalize behaviors based on the data of a few users. Thus, the more the merrier. Higher sample size also helps nullify any skews that we could see from outliers.
However, on a rather large e-commerce site that brings in at least 1,000 users per day, there is no way I would consider 100 and appropriate sample size of users. It’s all about proportions and what is a typical user volume for your site on a regular basis.
This variable includes conversions as well as users for the goals that you will be taking into account. Even if you have a low-converting site, if you compare 0 conversions to 2 conversions the variation with 2 conversions will most definitely win purely because it was the only variation to technically convert.
Make sure your conversions are at least in the double digits; and if that is your bare minimum (double digits), make sure you have strong complimenting action in the other three variables.
Or, if you don’t have much experience with sample size in a statistical setting, you can use this handy-dandy sample size calculator to determine an appropriate sample size for you.
Variable #2: Test Duration
Ideally, I run tests anywhere from 2-6 weeks.
Two weeks is a solid minimum because you’re nullifying the possibility of any variable having a “good” or a “bad” week and either hauling in happy traffic or driving away low-motivated traffic. Six weeks is a lovely maximum because it’s a wide enough temporal net to capture any fluctuations you could see.
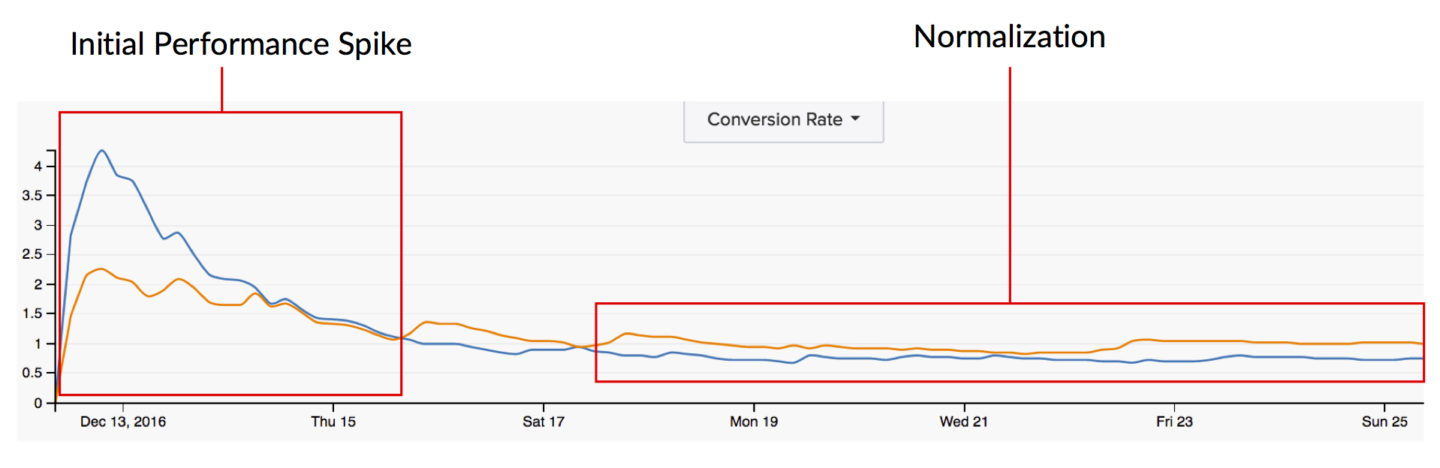
However, note that running a test forever and ever can also be detrimental to your test. A large factor in test results is user response to novel stimuli. Thus, when we first launch a test we tend to see huge leaps out of the gate where one variation is losing dramatically while the other coasts on its winning streak. Over time this huge gap between variations tends to normalize and close because the “new” has worn off and the returning users aren’t as affected by the novel alteration as they once were. Thus, the longer the test runs, the less novel the alteration gets and the less it influences behaviors for those return users.
Variable #3: Statistical Significance
While statistical significance is critical in declaring “confidence” in your conclusion, it can also be very misleading.
Statistical significance determines whether a change in two rates is due to normal variance or due to an outside factor. Thus, in theory, when we reach a strong statistical significance, we know that our alteration had an effect on the users.
Ideally, you want to aim for a statistical significance as close to 100% as possible. The closer you are to 100%, the smaller your margin of error is. This means that your results can be reproduced on a more consistent basis. The higher your statistical significance, the higher your chances of maintaining that conversion rate lift if you implement the winning variation. 95% is a good high goal to aim for. 90% is a good place to settle. Any lower than 90% and you’re getting risky with actually being able to “confidently” conclude.
The threat here is that sample size really matters. You could reach a statistical significance of 98% in a few days and literally only be looking at a total of 16 users which is obviously not a trustworthy sample size.
Statistical significance can also capture that huge spike in performance that I referenced earlier when a test is first launched. Tests have every capability of flip-flopping and we also know that over time the data normalizes. Thus, measuring statistical significance too early could give us a completely incorrect picture of how that alteration will most likely affect our users on a more long-term basis.
Furthermore, not every test is going to gain statistical significance. Some alterations that you make may not influence user behavior strongly enough to be seen as more than normal variance. And that’s fine! That simply means you need to test bigger alterations to capture a user’s attention a bit more.
Variable #4: Data Consistency
This one goes out to all those flip-flopping tests out there. There are some tests that refuse to normalize and refuse to present you with a clear winner. They’ll spend each day presenting you with a different variation as the winner and they will drive you absolutely bonkers.
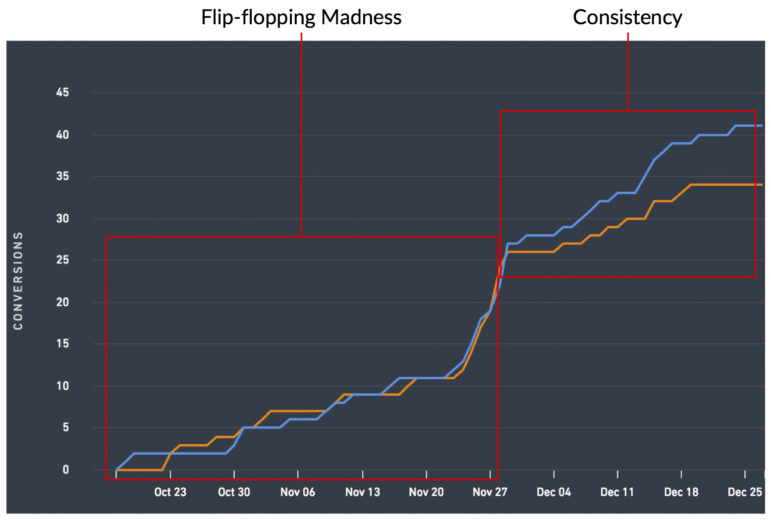
But they exist and they are exactly why looking for consistent data directionality is so crucial. Has the variation that you’re declaring a winner always been a winner? If not, why wasn’t it always a winner? If you cannot confidently answer the “why?” then implementing the winner could injure your bottom line if you implement the variation parading around as a winner.
I also measure the difference between the control’s conversion rate and the variation’s conversion rate (a.k.a. “lift” or “drop”). I look for this metric to be consistent as well so that I can ensure the test is out of the initial spike phase.
It’s also beneficial to calculate statistical significance periodically to see how consistent this metric is presenting as well.
Final Thoughts
Concluding any type of test is no joke and is filled with pressure. If you make the wrong call and implement something that you “felt” was the winner while the data was illustrating otherwise, your bottom line and your users will suffer.
Approach a conclusion from every viable angle so that you can ensure you have a truly confident conclusion fueled by data!
